Ô tô nhỏ hơn 150 pixel. Tổ ong chỉ vỏn vẹn 15 pixel. Liệu các mô hình deep learning hiện đại có đủ tinh nhạy để “nhìn thấy” những đối tượng rất nhỏ như vậy trên ảnh viễn thám không? Một nghiên cứu được đăng tải trên trang web arxiv.org và công bố năm 2026 trên tạp chí Expert Systems with Applications đã trả lời câu hỏi này bằng cách đưa 6 kiến trúc deep learning nổi bật vào một thử nghiệm với ba tập dữ liệu ảnh viễn thám độ phân giải cao. Hãy cùng VSGA phân tích kết quả để thấy được đâu là mô hình học sâu mang lại hiệu quả nhất cho bài toán nhận diện đối tượng nhỏ trong ảnh vệ tinh.
Đối tượng nhỏ trong ảnh vệ tinh — nhỏ đến mức nào?
Định nghĩa dựa trên pixel: Cách tiếp cận mới từ nghiên cứu 2026
Thay vì sử dụng tỷ lệ tương đối so với kích thước ảnh, nghiên cứu xác định đối tượng nhỏ dựa thuần túy trên số lượng pixel, cụ thể là diện tích dưới 32 × 32 pixel. Cách định nghĩa này mang tính nhất quán cao, dễ áp dụng trong các pipeline xử lý ảnh tự động, và đặc biệt phù hợp với đặc thù của dữ liệu viễn thám — nơi độ phân giải không gian của ảnh ảnh hưởng trực tiếp đến kích thước biểu kiến của đối tượng.
Ô tô và tổ ong — Hai đối tượng khó nhận diện trên ảnh viễn thám
Hai đối tượng thực nghiệm được chọn đại diện cho hai lĩnh vực ứng dụng hoàn toàn khác nhau:
- Xe hơi (đô thị): Dưới 150 pixel trong ảnh vệ tinh đô thị, dễ bị nhầm lẫn với các đối tượng hình chữ nhật khác như bóng đổ, mái nhà hay vệt đường kẻ.
- Tổ ong (nông nghiệp): Chỉ khoảng 15 pixel hoặc ít hơn, gần như không thể phân biệt bằng mắt thường và là một trong những thách thức nhận diện khó nhất trong lĩnh vực deep learning ứng dụng viễn thám.

6 Mô hình Deep Learning — 6 cách “nhìn” khác nhau
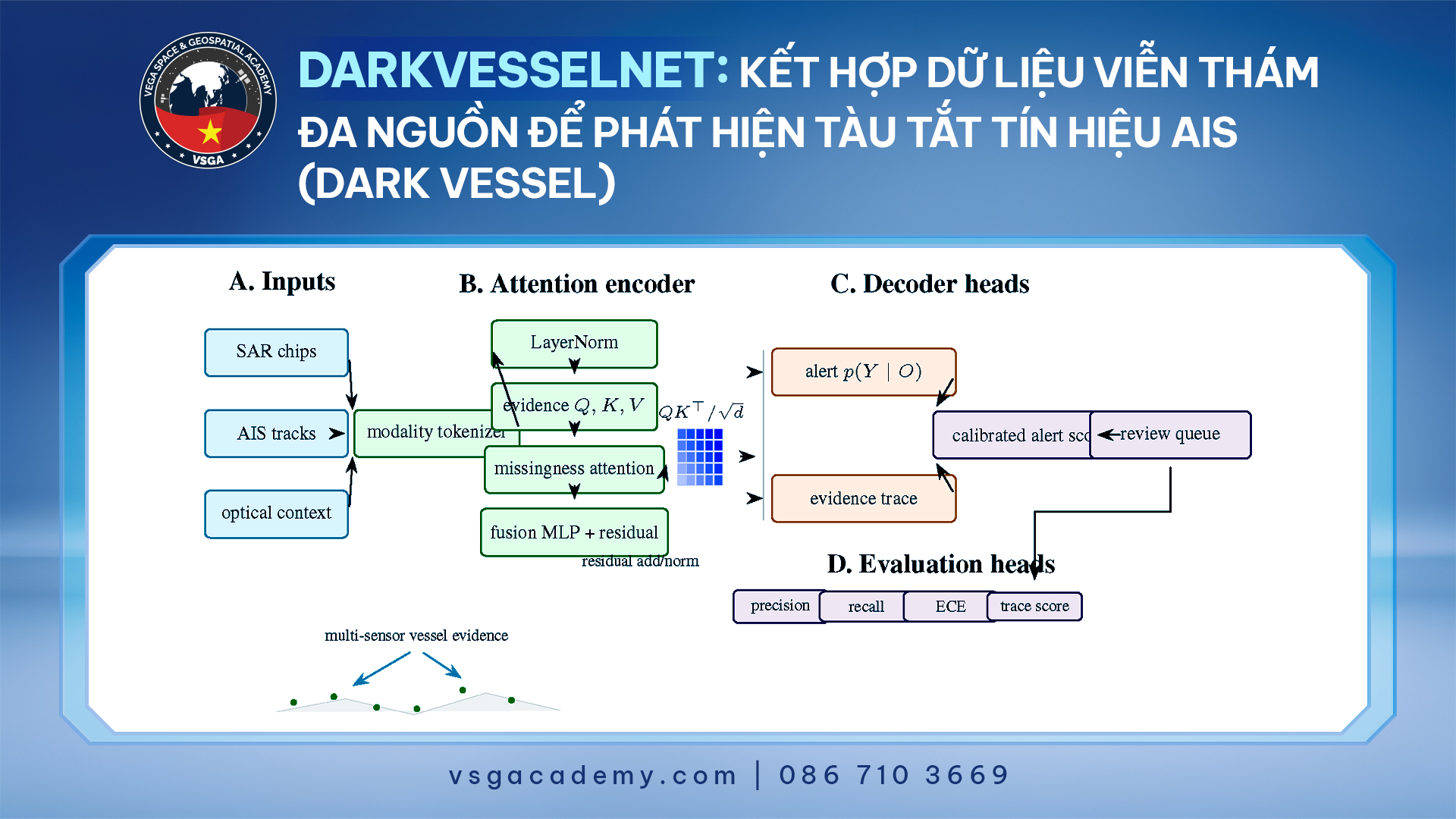
Nghiên cứu lựa chọn 6 mô hình đại diện cho 3 nhóm kiến trúc chính trong bài toán nhận diện đối tượng. Bên cạnh đó, hai phương pháp được thiết kế đặc biệt cho bài toán nhận diện đối tượng nhỏ cũng được đưa vào so sánh: FocusDet (kiến trúc hai tầng tương tự Faster R-CNN) và FFCA-YOLO — Feature Enhancement, Fusion and Context Aware YOLO (biến thể của YOLO).
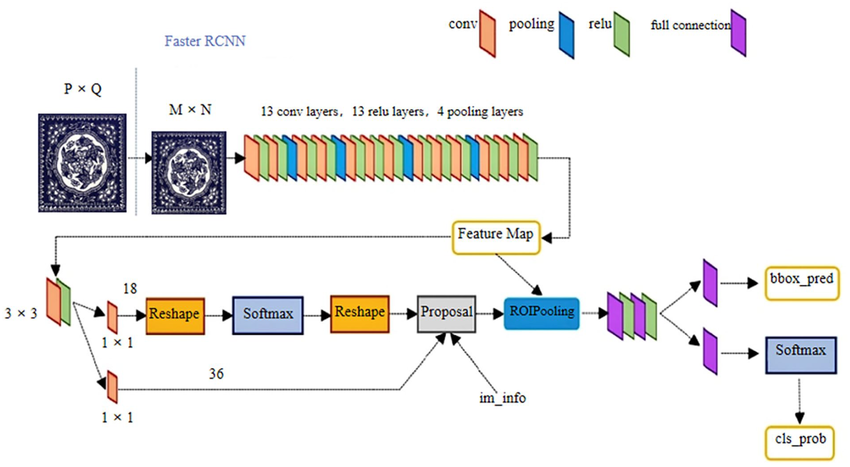
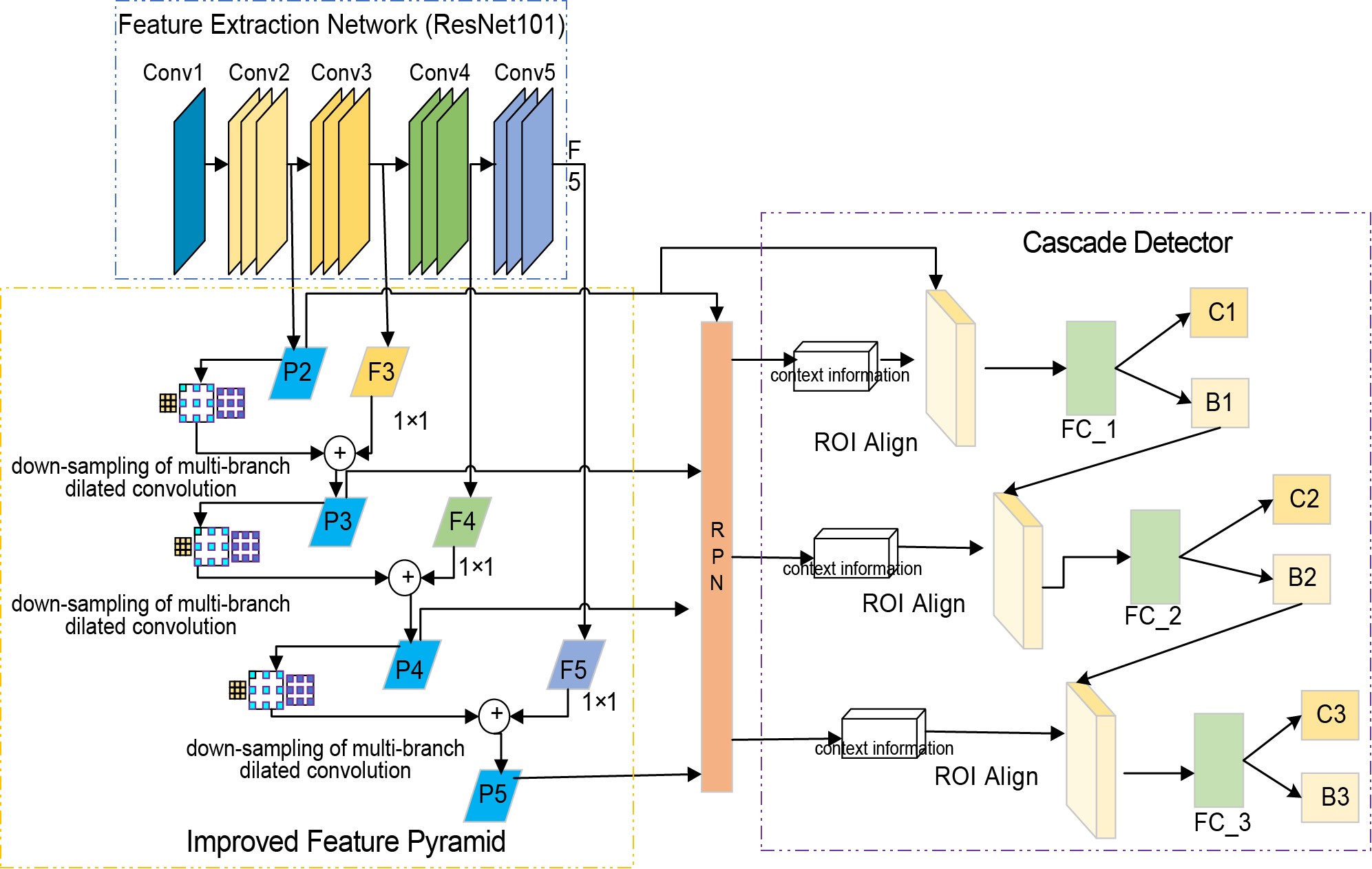
Faster R-CNN & Cascade R-CNN
- Cơ chế: Tìm vùng nghi vấn trước, phân loại sau (“nhìn hai lần”).
- Đặc điểm: Định vị chính xác nhờ tinh chỉnh nhiều bước, nhưng tốc độ chậm và dễ làm mất chi tiết đối tượng cực nhỏ khi qua các lớp xử lý sâu.
SSD
- Cơ chế: Dự đoán trực tiếp đối tượng dựa trên các khung hình học định sẵn.
- Đặc điểm: Tốc độ xử lý nhanh là lợi thế rõ ràng, song SSD kém hiệu quả trong nhận dạng đối tượng nhỏ do thiếu cơ chế kết hợp thông tin xuyên suốt giữa các lớp bản đồ đặc trưng — điểm yếu so với các mô hình deep learning thế hệ sau.
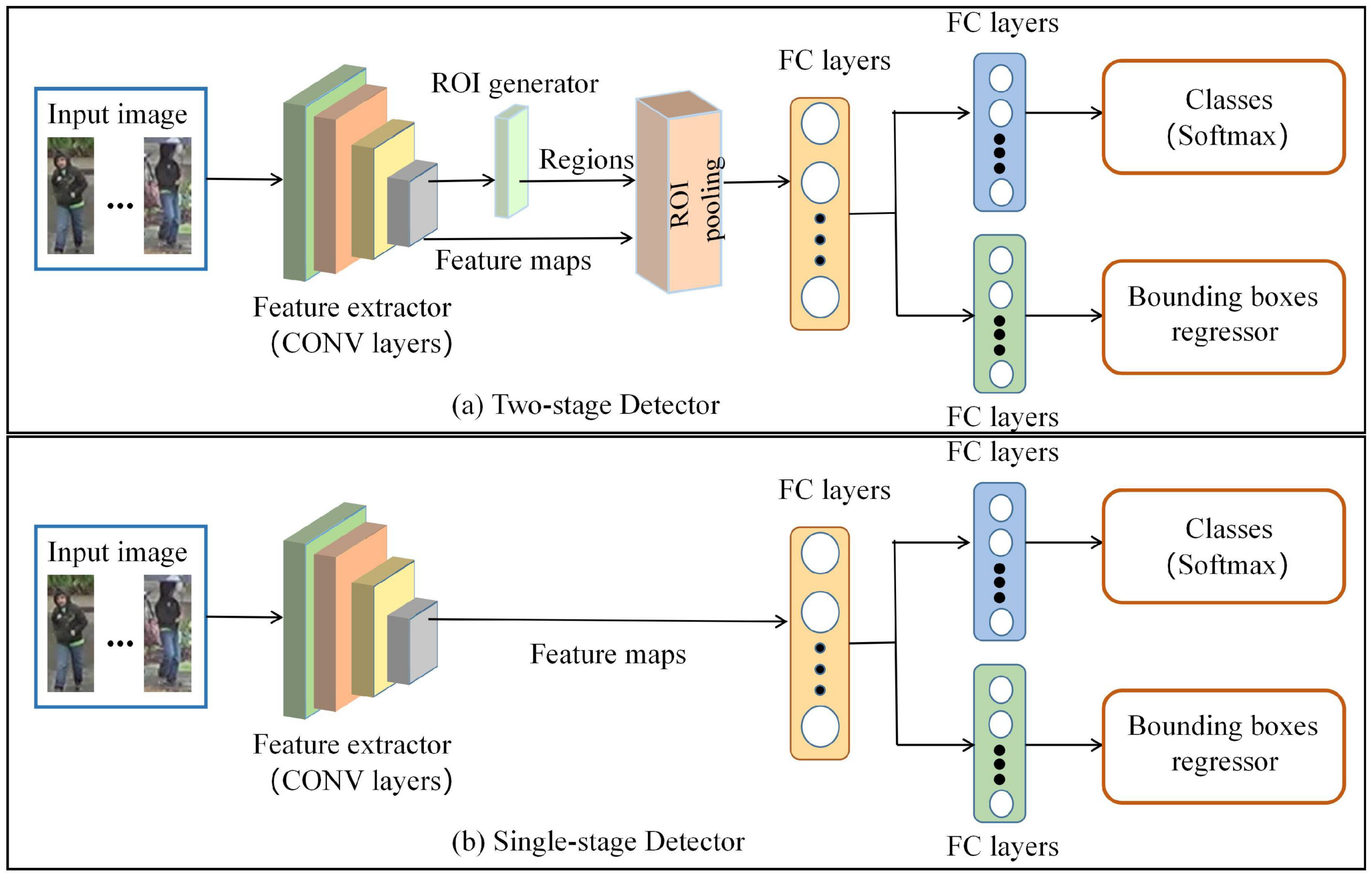
YOLOv11
- Cơ chế: Dự đoán trực tiếp tọa độ mà không cần khung mẫu.
- Đặc điểm: là mô hình deep learning đạt được sự cân bằng tốt nhất giữa độ chính xác nhận diện và tốc độ. Cơ chế chú ý giúp mô hình tập trung vào các vùng quan trọng, đặc biệt hữu ích khi đối tượng nhỏ xuất hiện trong bối cảnh nền phức tạp.
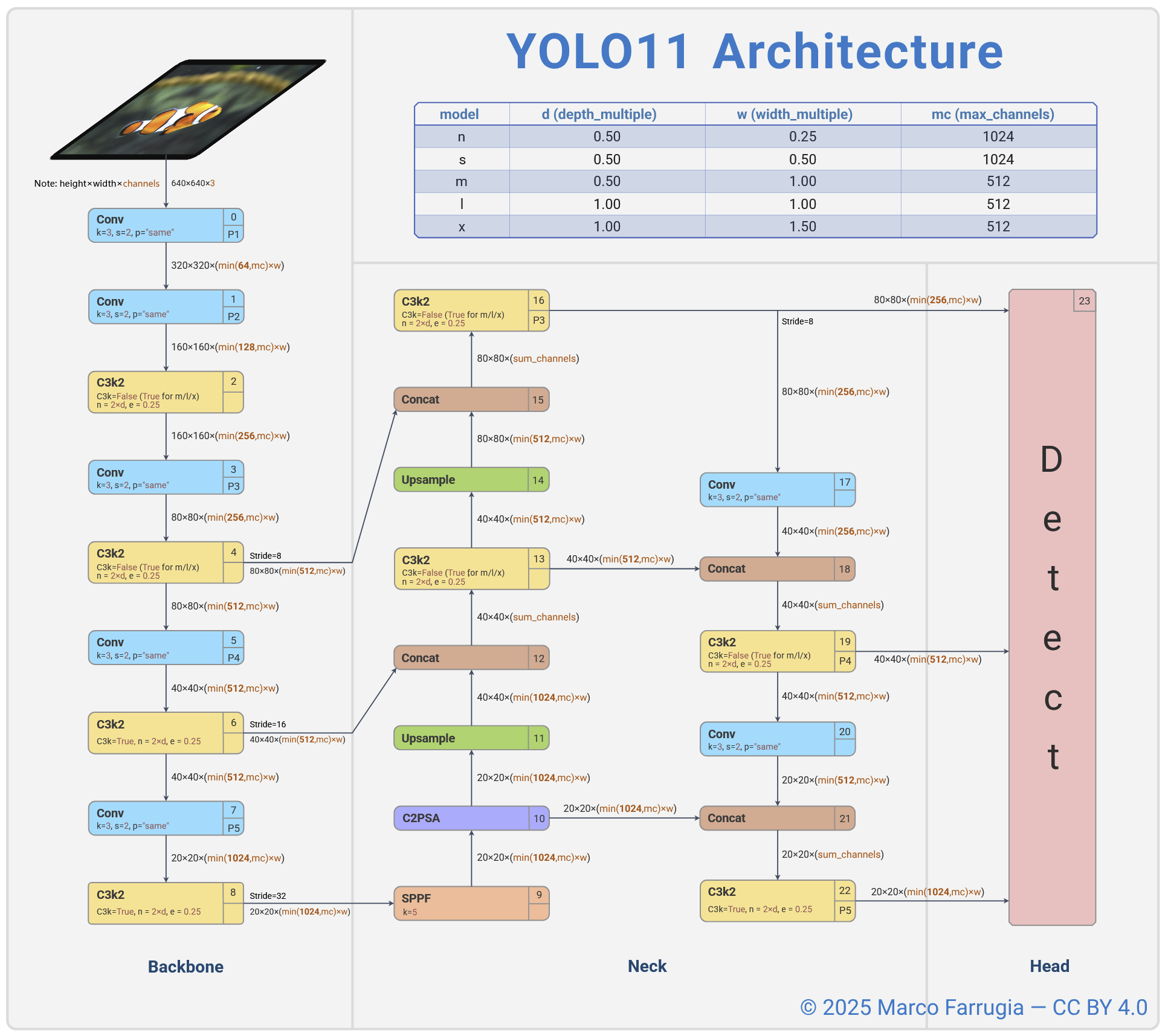
RT-DETR
- Cơ chế: Coi bức ảnh là một chuỗi thông tin và sử dụng cơ chế chú ý toàn cục.
- Đặc điểm: nổi bật trong nhận dạng đối tượng bị che khuất nhờ khả năng suy luận ngữ cảnh mạnh mẽ. Tuy nhiên, chi phí tính toán rất cao khiến mô hình deep learning này đòi hỏi phần cứng mạnh khi triển khai ở quy mô thực tế.
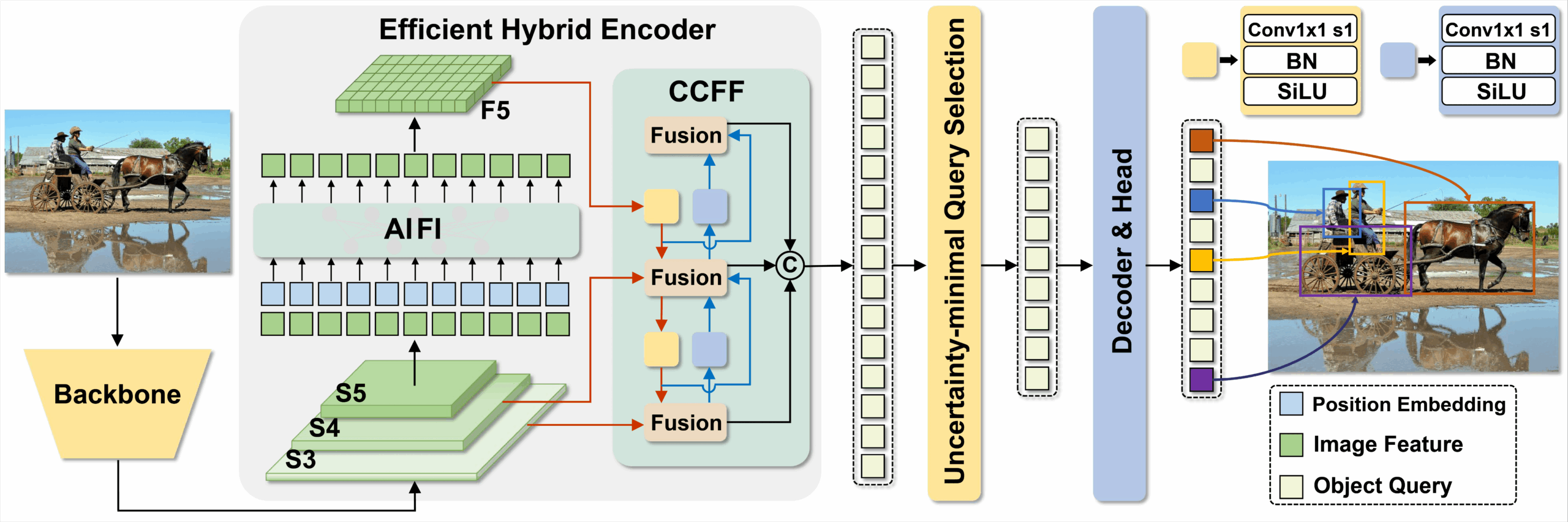
Deformable DETR
- Cơ chế: Chỉ tập trung vào một số điểm lấy mẫu quan trọng để giảm tải tính toán.
- Đặc điểm: Tương đối hiệu quả, song dễ bị nhầm lẫn (nhiễu) khi các đối tượng nhỏ nằm quá sát nhau.
Bảng so sánh tổng hợp
|
Mô hình |
Kiến trúc |
Khả năng nhận diện đối tượng nhỏ |
Khả năng nhận diện đối tượng bị che khuất |
Tốc độ |
Yêu cầu tài nguyên tính toán |
|
Faster R-CNN |
Hai giai đoạn, dùng khung mẫu, mạng đề xuất vùng |
Trung bình |
Trung bình |
Chậm |
Trung bình |
|
Cascade R-CNN |
Đa giai đoạn, dùng khung mẫu, mạng đề xuất vùng |
Trung bình |
Khá tốt |
Chậm |
Cao |
|
SSD |
Một giai đoạn, dùng khung mẫu, đa quy mô |
Yếu |
Yếu |
Nhanh |
Nhẹ |
|
YOLOv11 * |
Một giai đoạn, không khung mẫu, kết hợp CSP & FPN |
Tốt |
Tốt |
Nhanh |
Trung bình |
|
RT-DETR |
Transformer, cơ chế chú ý đa quy mô |
Tốt |
Rất rốt |
Trung bình |
Rất cao |
|
Deformable DETR |
Transformer, cơ chế chú ý biến dạng |
Khá tốt |
Khá tốt |
Trung bình |
Cao |
* YOLOv11: cân bằng nhất giữa hiệu suất và chi phí tính toán trong thực nghiệm.
Kết quả thực nghiệm — những phát hiện đáng chú ý:
Ba tập dữ liệu viễn thám được sử dụng trong thực nghiệm:
- xView: Ảnh đa phổ độ phân giải 0,3 m/pixel, gồm 60 lớp đối tượng.
- SkySat: Độ phân giải 0,5 m/pixel, bao gồm tổ ong nuôi trong bối cảnh nông nghiệp.
- DOTA: Tập hợp ảnh máy bay/UAV và ảnh vệ tinh đa nguồn.
Ảnh được chia thành các ô 512 × 512 pixel, tỷ lệ 70/30 cho tập huấn luyện và kiểm tra. Tối ưu siêu tham số được thực hiện bằng Optuna. Từ kết quả thực nghiệm, nhóm nghiên cứu rút ra một số phát hiện quan trọng có giá trị ứng dụng cao cho các bài toán deep learning trong ứng dụng viễn thám.


Vai trò then chốt của hộp neo (anchor box) và Feature Pyramid Network (FPN)
- Kích thước hộp neo (anchor box) có ảnh hưởng quyết định đến hiệu suất của các mô hình. Các mô hình như Faster R-CNN sẽ thất bại hoàn toàn nếu dùng cấu hình mặc định. Hiệu suất chỉ tăng vọt khi điều chỉnh kích thước hộp neo về mức ~90 pixel và tỷ lệ hộp neo (0,75–0,95) sát với hình dạng thực tế của đối tượng trong ảnh viễn thám.
- Feature Pyramid Network (FPN) là thành phần bắt buộc trong kiến trúc deep learning cho bài toán đối tượng nhỏ. FPN duy trì thông tin ở nhiều quy mô không gian khác nhau, ngăn mô hình “bỏ quên” các đối tượng cực nhỏ trong quá trình xử lý.
Cơ chế chú ý
Với các mô hình Transformer, con số tối ưu là khoảng 8 đầu chú ý cho các tập dữ liệu viễn thám đặc thù, sử dụng nhiều hơn có thể gây ra hiện tượng quá khớp (overfitting).
Khoảng cách miền dữ liệu (Domain gap) — Rào cản lớn nhất khi triển khai thực tế
Thực nghiệm cho thấy các mô hình deep learning có thể chuyển đổi tương đối tốt giữa các bối cảnh địa lý khác nhau với cùng một loại đối tượng (ví dụ: xe hơi ở các thành phố khác nhau). Tuy nhiên, hiệu suất giảm sút nghiêm trọng khi đối tượng thay đổi hoàn toàn về hình thái (ví dụ: từ xe hơi sang tổ ong). Khoảng cách miền dữ liệu (domain gap) vẫn là rào cản lớn nhất khi triển khai các hệ thống nhận diện deep learning trong ứng dụng viễn thám thực tế.
Kết luận: phương pháp Deep Learning nào phù hợp để nhận diện đối tượng nhỏ trong ảnh viễn thám?
YOLOv11 — Lựa chọn thực tiễn cho dữ liệu viễn thám độ phân giải cao
Trên cơ sở đánh giá tổng thể, nghiên cứu cho thấy YOLOv11 có thể là lựa chọn tốt cho các bài toán nhận diện đối tượng nhỏ từ ảnh viễn thám độ phân giải cao trong điều kiện tài nguyên tính toán thực tế. Mô hình deep learning này đạt được sự cân bằng tốt nhất giữa độ chính xác, tốc độ và chi phí vận hành — ba tiêu chí quan trọng khi triển khai hệ thống giám sát đô thị hoặc nông nghiệp từ ảnh vệ tinh.
Hướng phát triển tương lai của Deep Learning
Để cải thiện hiệu quả của deep learning cho các bài toán nhận diện đối tượng nhỏ, nghiên cứu đề cập đến ba hướng phát triển chính:
- Kiến trúc lai (Hybrid Architecture): Kết hợp ưu điểm của lớp tích chập (CNN) với cơ chế attention
- Foundation Model cho viễn thám: Tiền huấn luyện (pre-training) trên khối lượng dữ liệu không nhãn khổng lồ giúp mô hình deep learning có “tri thức nền” tốt hơn trước khi tinh chỉnh (fine-tuning) cho từng tác vụ cụ thể, giảm đáng kể nhu cầu dữ liệu nhãn tốn kém.
- Học đa mô thức (Multi-modal Learning): Nơi các bộ phát hiện có thể tận dụng các nguồn dữ liệu bổ sung như ảnh đa phổ.
Nguồn: An empirical analysis of deep learning methods for small object detection from satellite imagery
Đọc miễn phí tại: https://arxiv.org/html/2502.03674v1