VSGA tổng hợp và chia sẻ đến độc giả nghiên cứu gần đây được chấp thuận tại hội nghị SPIE Defense + Security 2026: nhóm tác giả từ Đại học Bang Arizona đã đề xuất phương pháp huấn luyện mô hình đa phương thức nhằm theo dõi và diễn giải tiến trình các công trình xây dựng quy mô lớn từ dữ liệu viễn thám. Nghiên cứu thực hiện thông qua việc tái cấu trúc bộ dữ liệu SMART-HC-VQA và chuẩn hóa quy trình xử lý thực nghiệm.
Bối cảnh: vì sao cần mô hình ngôn ngữ cho ảnh vệ tinh?
Các hệ thống phát hiện thay đổi từ ảnh vệ tinh đã được nghiên cứu trong nhiều thập kỷ, tuy nhiên cho tới hiện tại chủ yếu mới dừng lại ở việc trả lời câu hỏi “Có sự thay đổi hay không?”, mà chưa lý giải bản chất của sự thay đổi, các mốc thay đổi, xu hướng tiếp diễn hay ý nghĩa đằng sau các biến động đó.
Nghiên cứu hướng đến mục tiêu lớn hơn: xây dựng khả năng hiểu và diễn giải hoạt động thay đổi của một đối tượng địa lý theo thời gian bằng ngôn ngữ tự nhiên, tập trung vào các công trình xây dựng quy mô lớn (heavy construction) — những đối tượng có quá trình biến động rõ ràng từ giải phóng mặt bằng đến hoàn thiện công trình.
Năm thách thức đặc thù của dữ liệu viễn thám
- Giới hạn về độ phân giải (10m/pixel với Sentinel-2)
- Quan sát không liên tục do ảnh hưởng bởi mây và quỹ đạo của vệ tinh
- Biến động đa thời gian phức tạp (ảnh cách nhau nhiều tháng/năm)
- Thiếu dữ liệu đã được gán nhãn bằng ngôn ngữ tự nhiên
- Hiện tượng dịch chuyển phân phối (domain shift) khiến các mô hình ngôn ngữ lớn (LLM) và mô hình ngôn ngữ thị giác (VLM) đã được huấn luyện bằng ảnh tự nhiên (ảnh 3 màu RGB) không hoạt động tốt khi chuyển sang dùng với dữ liệu là ảnh vệ tinh.
Từ nhận diện tự động đến hỏi đáp bằng ngôn ngữ tự nhiên
Nghiên cứu được thực hiện trong khuôn khổ chương trình IARPA SMART với ba nhiệm vụ:
- Broad Area Search (BAS): Phát hiện và định vị hoạt động xây dựng trong không gian và thời gian
- Activity Classification (AC): Gán nhãn giai đoạn hoạt động tại mỗi điểm quan sát
- Activity Prediction (AP): Dự đoán trạng thái tương lai của địa điểm.
Ba đóng góp chính của nghiên cứu
- Bộ dữ liệu SMART-HC-VQA: chuyển bộ dữ liệu ảnh vệ tinh IARPA SMART thành dạng “hỏi-đáp bằng hình ảnh” (VQA), tức là cho mô hình xem ảnh rồi đặt câu hỏi và yêu cầu trả lời. Đây là bộ dữ liệu VQA đầu tiên cho viễn thám có khả năng so sánh nhiều ảnh chụp ở các thời điểm khác nhau.
- Image-Pairwise Combinatorial Augmentation (kỹ thuật tăng cường dữ liệu bằng cách ghép cặp ảnh): thay vì chỉ ghép các ảnh chụp liên tiếp nhau, kỹ thuật này ghép tất cả các cặp ảnh có thể của cùng một địa điểm, bao gồm cả những cặp cách nhau nhiều tháng hoặc nhiều năm. Nhờ vậy, từ 21,837 mảnh ảnh nhỏ (chips) ban đầu, nhóm tác giả tạo ra được khoảng 2,3 triệu cặp ảnh để huấn luyện.
- Multi-Image MLLM Training Framework (khung huấn luyện mô hình đa phương thức nhiều ảnh): quy trình huấn luyện mô hình LLaVA-NeXT Mistral-7B sao cho nó có thể nhận cùng lúc nhiều ảnh vệ tinh kèm theo thời điểm chụp, từ đó hiểu được sự thay đổi của một địa điểm theo thời gian, thay vì chỉ phân tích từng ảnh riêng lẻ.
Bộ dữ liệu SMART-HC-VQA
SMART-HC-VQA là bộ dữ liệu VQA đầu tiên được thiết kế chuyên biệt cho phân tích không-thời gian hoạt động xây dựng từ ảnh Sentinel-2. Mục tiêu là cho phép AI theo dõi diễn biến công trường và trả lời các câu hỏi như “Đây là công trình gì?”, “Đang ở giai đoạn nào?”, “Đã thay đổi ra sao?”.
|
Thành phần |
Số lượng |
|
Ảnh Sentinel-2 chips |
21,837 |
|
Mẫu VQA (theo 1 ảnh) |
65,511 |
|
Mẫu VQA (so sánh 2 ảnh theo thời gian) |
~ 2,300,000 |
Bảng 1. Quy mô bộ dữ liệu SMART-HC-VQA
Quy trình xử lý dữ liệu Sentinel-2
Dữ liệu ảnh vệ tinh Sentinel-2 được xử lý qua ba bước chính:
- Bước 1: Ảnh được thu thập từ hai nguồn là Google Earth Engine và Copernicus Hub
- Bước 2: Ảnh được chia nhỏ thành các mảnh (tiling) để thuận tiện cho quá trình xử lý
- Bước 3: Phân tích phân phối dữ liệu trên nhiều chiều, bao gồm kích thước ảnh, số lần quan sát, khoảng thời gian ghi nhận, cũng như loại hình và giai đoạn xây dựng tương ứng

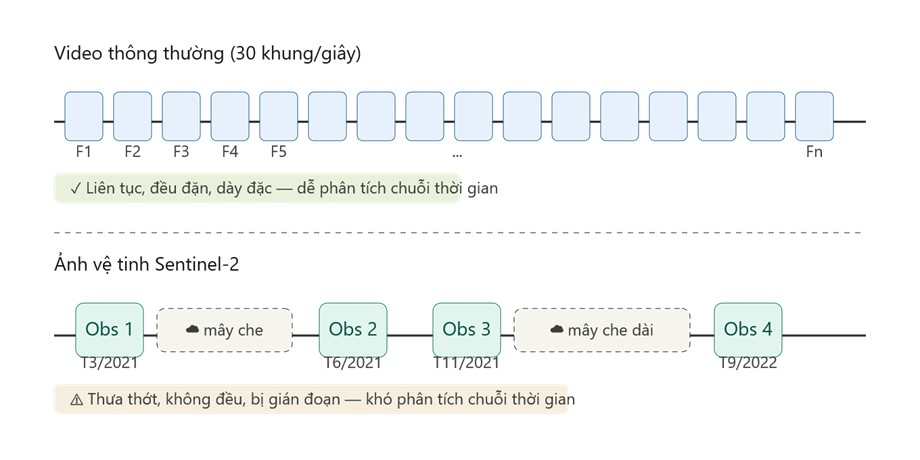
Kỹ thuật Image-Pairwise Combinatorial Augmentation
Khác với video thông thường 30 khung/giây liên tục, ảnh vệ tinh của một địa điểm chỉ có vài lần quan sát mỗi năm, không đều và bị gián đoạn bởi mây. Thay vì chỉ học từ các cặp ảnh liền kề (N-1 cặp cho N quan sát), kỹ thuật tổ hợp ghép tất cả cặp có thể, cho phép mô hình học thay đổi ở nhiều khoảng thời gian khác nhau — ngắn hạn, trung hạn và dài hạn.
Kiến trúc mô hình Multi-Image MLLM
Mô hình nền tảng là LLaVA-NeXT Mistral-7B — MLLM mã nguồn mở có hiệu suất cao, kiến trúc linh hoạt, cân bằng tốt giữa hiệu suất và chi phí tính toán. Vì mô hình LLaVA-NeXT nguyên bản chỉ nhận 1 ảnh đầu vào, nhóm tác giả đã điều chỉnh khung mô hình để: nhận nhiều ảnh kèm dấu mốc thời gian, mã hóa thông tin thời gian vào ngữ cảnh của mô hình ngôn ngữ, và huấn luyện trên các cặp hỏi-đáp được tự động sinh từ siêu dữ liệu SMART-HC.
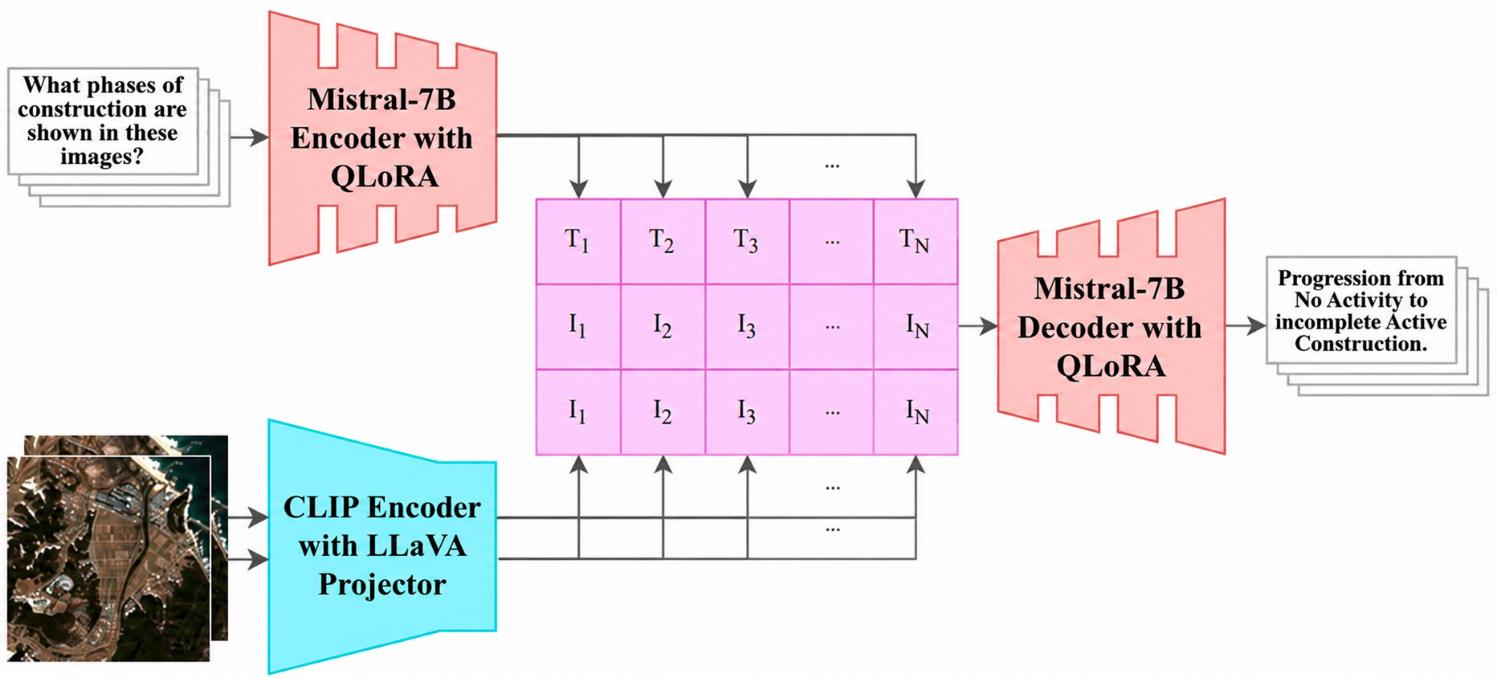
Đây là sự dịch chuyển từ việc tự động nhận diện (ATR – Automatic Target Recognition) truyền thống — vốn chỉ trả lời “phải/không phải” và “loại gì” — sang VQA: hệ thống hiểu và diễn giải những gì xảy ra tại một địa điểm qua nhiều tháng/năm bằng ngôn ngữ tự nhiên.
So sánh với các công trình liên quan
|
Phương pháp |
Nguồn dữ liệu |
Nhiều ảnh |
Hỏi đáp thời gian |
Quy mô |
|
RSVQA (Lobry et al.) |
Sentinel-1/2 |
Không |
Không |
~77K |
|
GeoLLaVA |
Tự xây dựng |
Video |
Có |
Nhỏ |
|
TEOChat |
Tự xây dựng |
Có |
Có |
Vừa |
|
ChangeChat |
Tự xây dựng |
Có (2 ảnh) |
Có |
Vừa |
|
SMART-HC-VQA |
IARPA SMART |
Có |
Có |
~2.37 triệu |
Bảng 2. So sánh SMART-HC-VQA với các bộ dữ liệu VQA viễn thám hiện có
Không những có số lượng mẫu lớn, SMART-HC-VQA còn dựa trên các nhãn (annotation) của IARPA và Johns Hopkins APL – hai tổ chức uy tín hàng đầu trong tình báo địa không gian, giúp đảm bảo chất lượng nhãn cao hơn hẳn các bộ dữ liệu tự xây dựng.
Đánh giá mô hình ngôn ngữ đa phương thức
Điểm mạnh
- Quy mô ~2.37 triệu mẫu, là bộ dữ liệu tiêu chuẩn (benchmark) VQA thời gian lớn nhất trong viễn thám.
- Chất lượng dữ liệu cao nhờ nhãn (annotation) từ IARPA và JHU-APL.
- Tính tái lập tốt: quy trình mô tả chi tiết, có thể tái thực hiện.
- Kỹ thuật tăng cường tổ hợp đơn giản nhưng hiệu quả, biến điểm yếu (thưa thớt) thành lợi thế học tập.
- Tác giả trung thực về phạm vi: đây là nền tảng, không phải giải pháp hoàn chỉnh.
Điểm hạn chế
- Chưa có kết quả đánh giá định lượng (BLEU, BERTScore, độ chính xác).
- Chỉ dùng Sentinel-2, bỏ qua các nguồn ảnh độ phân giải cao hơn.
- Câu hỏi sinh tự động từ mẫu cố định có nguy cơ thiếu đa dạng ngôn ngữ.
- Không so sánh với các mô hình lớn như GPT-4V hay Gemini trên cùng bài toán.
Định hướng phát triển
- Ngắn hạn: hoàn thiện đánh giá định lượng, so sánh với các MLLM khác và công bố kết quả trên tập kiểm thử.
- Trung hạn: tích hợp bộ nhớ ngữ cảnh dài hạn cho từng địa điểm; kết hợp radar Sentinel-1 với Sentinel-2 để khắc phục mây che; mở rộng sang dự đoán các giá trị định lượng.
- Dài hạn: suy diễn ý định đằng sau hoạt động; tổng quát hóa sang giám sát cảng biển, hàng hải, mở rộng đô thị, nông nghiệp.
Kết luận
Thay vì tham vọng giải quyết trọn vẹn một bài toán phức tạp, nghiên cứu này tập trung xây dựng nền móng vững chắc cho cộng đồng. SMART-HC-VQA lấp đầy khoảng trống trong hỏi đáp với hình ảnh (VQA) theo thời gian cho viễn thám; kỹ thuật tổ hợp cặp ảnh biến sự thưa thớt – điểm yếu của dữ liệu vệ tinh thành lợi thế học tập; còn khung huấn luyện đa ảnh dựa trên LLaVA-NeXT mở đường cho việc tinh chỉnh các mô hình ngôn ngữ đa phương thức trên những miền dữ liệu đặc thù.